
Communication between a user agent and an origin server using a tunnel.
The World Wide Web is based on a client server model in which clients (web browsers) make requests to servers (web servers). There are three main aspects:
Locating Resources
URI (Uniform Resource Identifier): a formatted string that identifies a resource
by name, location, or other characteristics.
The most common form:
URL (Uniform Resource Locator): has the form
scheme:location
scheme is a method for access, such as http or ftp.
location indicates the location, usually with a host name and a path.
The http URL looks like:
"http://" host [ ":" port ] [abs_path [ "?" query]]
Examples:
http://www.google.com
/classes/cs3733s2002/syllabus.html
http://www.pup.cs.utsa.edu:8080/pup2/index.html
http://www.google.com/search?hl=en&q=UTSA
HTTP
HTTP stands for HyperText Transfer Protocol
This is a request-reply protocol that assumes that messages are delivered
reliably. It is usually run over TCP using the default port of 80.
In HTTP, the client requests a connection and sends a number of header lines
which are ASCII characters terminated by CRLF.
After sending a line containing only CRLF, binary content information
may be sent.
The server responds with similar header lines followed by optional binary
content.
When the request-reply is completed, the connection is closed.
The first header line sent by the client has the form:
Method space Request-URI spaceA HTTP-Version CRLF
Additional header lines have the form:
Field-Name:Field-value CRLF
The first response line from the server is a status line that has the form
HTTP-Version space Status-Code space Reason-Phrase CRLF
You can use the client2 program of Chapter 12 (PUP2) to communicate
with a web server.
Start the program with:
client2 vip.cs.utsa.edu 80
and then type the following:
GET /pup2/notthere.html HTTP/1.0Where only a RETURN was pressed on the last line.
HTTP/1.1 404 Not Found Date: Mon, 01 Apr 2002 13:37:50 GMT Server: Apache/1.3.4 (Unix) Connection: close Content-Type: text/html <!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN"> <HTML><HEAD> <TITLE>404 Not Found</TITLE> </HEAD><BODY> <H1>Not Found</H1> The requested URL /pup2/notthere.html was not found on this server.<P> <HR> <ADDRESS>Apache/1.3.4 Server at vip.cs.utsa.edu Port 80</ADDRESS> </BODY></HTML> [12256]:Bytes transferred = 453
The following input to the same client2 program
GET /pup2/short.html HTTP/1.0would produce the following response:
HTTP/1.1 200 OK Date: Mon, 01 Apr 2002 13:44:27 GMT Server: Apache/1.3.4 (Unix) Last-Modified: Mon, 01 Apr 2002 13:44:02 GMT ETag: "9ffb6-7e-3ca86422" Accept-Ranges: bytes Content-Length: 126 Connection: close Content-Type: text/html <HTML> <HEAD> <TITLE>This is a short HTML Documnet</TITLE> </HEAD> <BODY> This is a very short HTML document. </BODY> </HTML> [12258]:Bytes transferred = 402
The three main methods used in HTTP 1.0 in the initial client request line are
There are two main forms of the Request-URI in an HTTP request.
The standard form, called an absolute path,
is just a path as illustrated above.
It requests a resource on the host it has connected to.
The other form is called an absolute URI and
begins with http://. It looks like a request
you would type into a browser.
It request that the resource be located on the indicated remote machine.
For example, if a host received the following GET request:
GET http://www.pup.cs.utsa.edu/pup2/index.html HTTP/1.0
requests that the receiving host make a connection to
www.pup.cs.utsa.edu and send it the following request:
GET /pup2/index.html HTTP/1.0
After that it will forward everything from the requesting client to
www.pup.cs.utsa.edu and everything from www.pup.cs.utsa.edu
back to the client.
Terminology
client: an application that establishes a connection
server: an application that accepts connections and responds
user agent: a client that initiates a request for service
origin server: a server that has a resource
Tunnels
A tunnel is an intermediary that acts as a blind rely.
It does not parse HTTP, but forwards everything to the server.
A tunnel is a client and a server but neither a user agent or an origin server.
This is illustrated in the figure below.
Communication between a user agent and an origin server using a tunnel.
A tunnel can protect an intranet behind a firewall.
As illustrated by the figure below, the user agent can only access the
origin server inside the firewall through the tunnel running on a machine
outside the firewall. The user agent does not even have to know of the existence of the machine vip.cs.utsa.edu. It believes that www.pup.cs.utsa.edu is
the origin server.
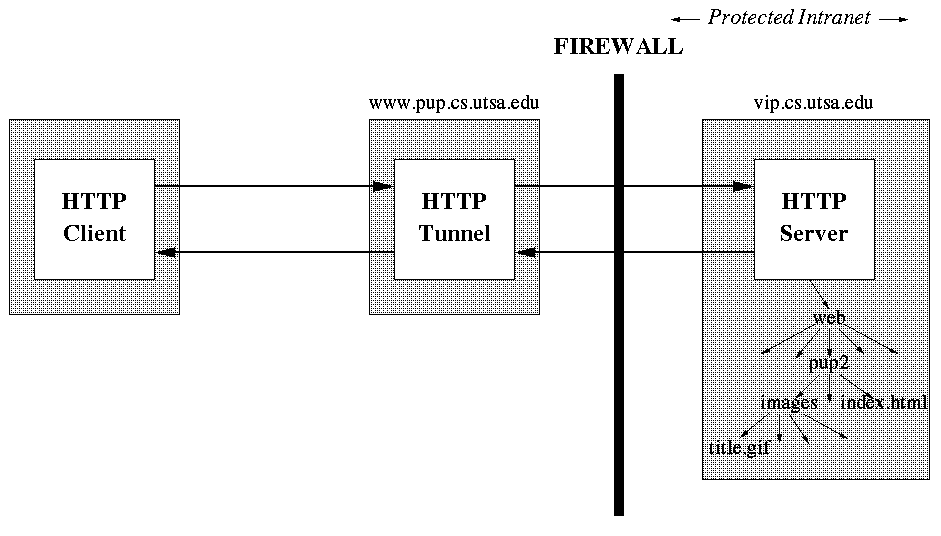
A tunnel used to provide controlled access through a firewall.
Proxies
A proxy is an intermediary between clients and servers that makes requests on behalf of the clients. Absolute URIs are sent to the proxy, the proxy parses the absolute URI and communicates with the server indicated in the absolute URI.
While a tunnel is usually set up to handle a single request, proxies are usually long-lived processes.
The figure below shows a proxy running on org.proxy.net.
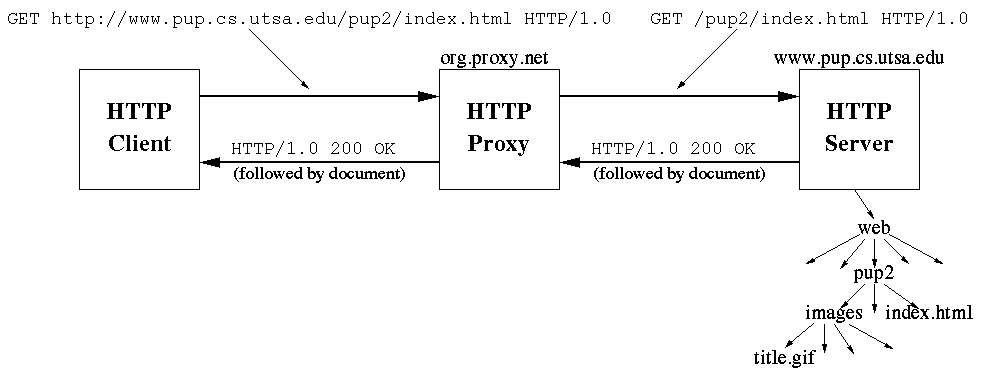
A proxy accesses a server on behalf of a client.
Proxies can be used for any of the following:
You can set up your browser to go send all requests through a proxy.
The figure below illustrates a proxy used for caching.
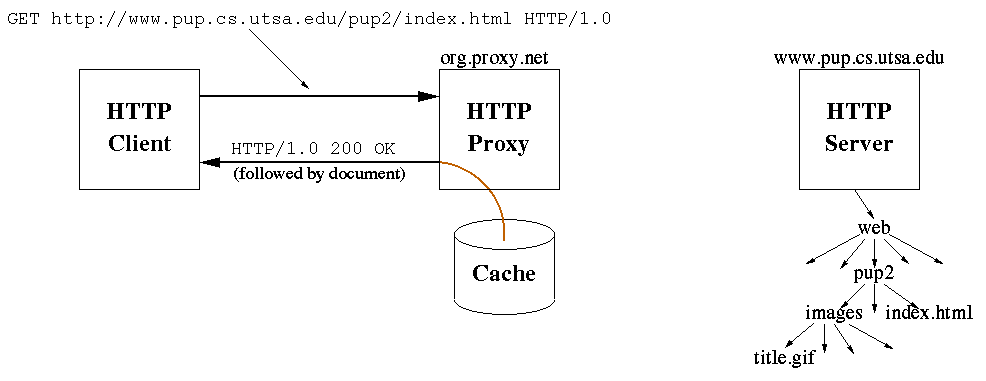
If possible, a proxy cache retrieves requested resources from its local store.